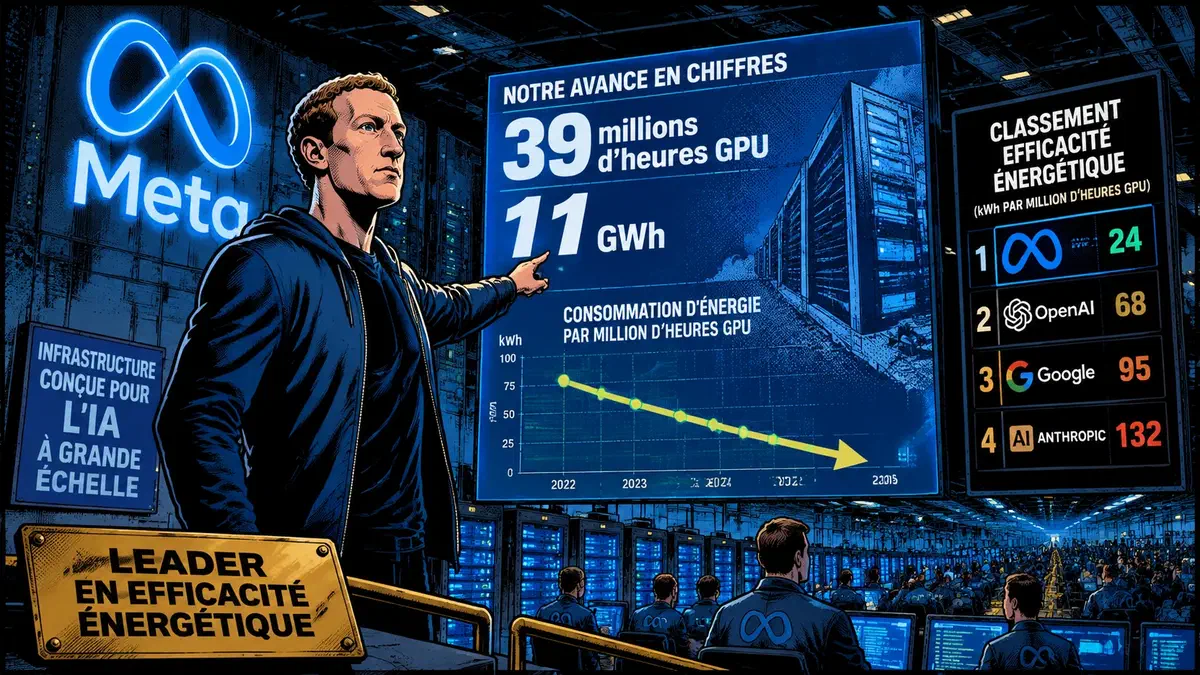
Entraîner un grand modèle de langage consomme autant d’électricité qu’une petite ville pendant plusieurs semaines. Llama 3.1, le prédécesseur direct, aurait mobilisé 39 millions d’heures de GPU, plus de 16 000 puces H100 et environ 11 GWh rien que pour son entraînement, selon des estimations relayées par Bon Pote en juin 2025. Meta connaît ces chiffres. Et avec Llama 4, l’entreprise affirme vouloir faire autrement.
La promesse est ambitieuse, le paradoxe aussi : pour y parvenir, Zuckerberg construit l’infrastructure la plus massive jamais annoncée publiquement.
Llama 4 : une architecture conçue pour dépenser moins à chaque requête
En mars 2025, Mark Zuckerberg décrivait à Reuters le cluster d’entraînement de Llama 4 comme « plus grand que 100 000 H100, plus grand que tout ce que j’ai vu rapporté sur ce que font les autres ». Un déploiement de puissance de calcul brute qui semble contredire l’ambition d’efficacité, jusqu’à ce qu’on comprenne la logique technique derrière.
Llama 4 repose sur une architecture Mixture-of-Experts (MoE). Le principe : au lieu d’activer l’intégralité des paramètres du modèle à chaque inférence, seule une fraction entre en jeu. Llama 4 Scout embarque 109 milliards de paramètres au total, mais n’en active que 17 milliards par requête. Llama 4 Maverick monte à 400 milliards de paramètres, avec le même volume actif de 17 milliards. C’est ce ratio qui détermine le coût énergétique réel à l’usage.
Cette approche n’est pas une invention de Meta. Mistral AI et DeepSeek l’ont popularisée en 2024. Mais Meta lui ajoute une fenêtre de contexte pouvant atteindre 10 millions de tokens sur certaines configurations, ce qui permet de traiter des documents longs en une seule passe. Moins d’itérations, moins de calcul, moins d’énergie dépensée par interaction.
L’efficacité comme argument commercial autant qu’environnemental
Reuters soulignait déjà fin 2024 que la question énergétique était devenue impossible à ignorer pour les grandes plateformes. Les discussions climatiques internationales de 2025 ont amplifié la pression. Quand Zuckerberg promet « un raisonnement plus fort et beaucoup plus rapide » tout en « réduisant considérablement les calculs requis, diminuant ainsi les coûts et la latence », il parle autant aux directeurs financiers qu’aux militants climatiques.
Ce positionnement sert une stratégie précise. Llama 4 est open source, et les entreprises qui déploient des modèles à grande échelle calculent leur facture GPU à la milliseconde. Un modèle qui consomme deux fois moins de calcul par requête, c’est une infrastructure deux fois moins coûteuse. L’argument vert et l’argument économique se superposent parfaitement, ce qui n’est pas toujours le cas dans l’industrie.
Les architectures MoE imposent leurs propres contraintes. Coordonner des experts spécialisés génère de la complexité à l’inférence, notamment en termes de mémoire et de routage. Tony Stark dirait qu’on n’obtient rien pour rien. Les benchmarks indépendants sur la consommation réelle des variantes Llama 4 en production restent, à ce stade, partiels.
Ce que ça change pour les entreprises françaises et européennes
La régulation européenne de l’IA a occupé Reuters tout au long des trois premiers mois de 2026. Dans ce contexte, les modèles open source présentent un avantage concret : les organisations peuvent les déployer sur leur propre infrastructure, contrôler leurs données et répondre plus facilement aux exigences de transparence imposées par l’AI Act.
Llama 4, s’il tient ses promesses d’efficacité, réduit aussi le ticket d’entrée pour les PME françaises qui veulent expérimenter l’IA générative sans se lier à un cloud américain ou engager des budgets GPU prohibitifs. Un modèle performant avec 17 milliards de paramètres actifs tourne sur une infrastructure très différente de GPT-4, dont Reuters évoquait en 2024 environ trois mois de calcul sur 25 000 GPU rien que pour l’entraînement.
La fenêtre de contexte à 10 millions de tokens intéresse aussi les secteurs à forte densité documentaire : juridique, médical, administration publique. Traiter un dossier complet en une requête plutôt qu’en dizaines d’appels successifs, c’est une différence opérationnelle réelle.
Et si l’efficacité énergétique devenait le prochain critère de certification pour les modèles d’IA déployés en Europe ?

